Reducing Downtime in Plants and Refineries: Practical Strategies that Work
Asset and Reliability Management
2/2/20264 min read
Reducing downtime in refineries and production plants isn’t about one “silver bullet”—it’s about tightening multiple weak links across maintenance, operations, and planning. In real plants, the biggest gains come from practical, disciplined execution rather than expensive technology alone.
Here are proven, field-tested strategies that actually work:
1) Shift from Reactive to Predictive Maintenance
Reactive maintenance is the biggest driver of unplanned downtime.
What works:
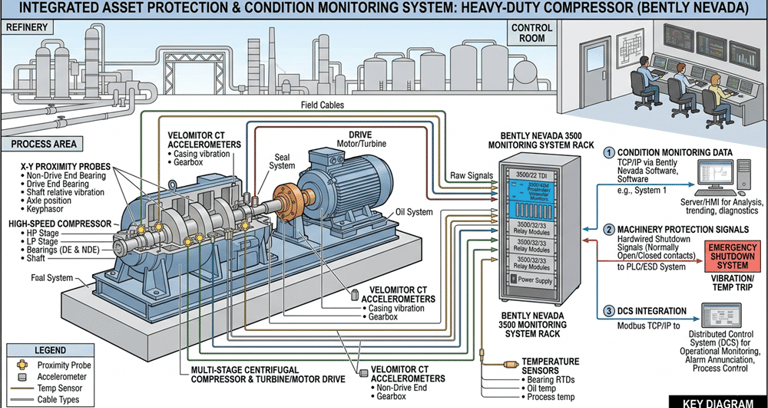
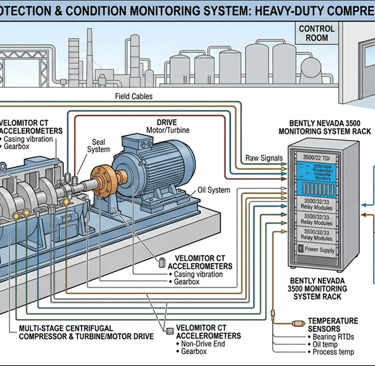
Deploy vibration monitoring on critical rotating equipment (compressors, pumps, turbines) -Bently Nevada is a classic and widely used example of an asset protection and condition monitoring system, especially for critical rotating equipment like Heavy Duty compressors -It provides real-time monitoring and protection for rotating equipment by continuously measuring key parameters such as:
v Vibration (radial & axial), Shaft displacement, bearing temperature, Speed / RPM, Phase reference, Position (thrust, eccentricity)
Sensors installed on equipment
v Proximity probes, Accelerometers, Temperature sensors, Signal processing system, Bently Nevada racks/modules (e.g., 3500 system), Converts raw signals into usable data
Continuous data transmission
v Sends signals to: Control Room (DCS / SCADA) ,Local monitoring systems
Visualization & alarms
v Operators see live machine condition, Alarm thresholds trigger warnings or trips
Asset Protection Function :
v If vibration exceeds safe limits → Alarm -If it reaches a dangerous level → Automatic trip/shutdown
This prevents:
Catastrophic compressor failure, Secondary damage to seals, bearings, or casing, Safety incidents and unplanned downtime
Use thermography for electrical systems and furnaces
Oil analysis for early detection of wear, contamination, and degradation
Set alarm thresholds tied to real failure modes—not generic OEM limits
Practical tip:
Start with the top 20% critical assets (Pareto rule). Don’t try to monitor everything at once.
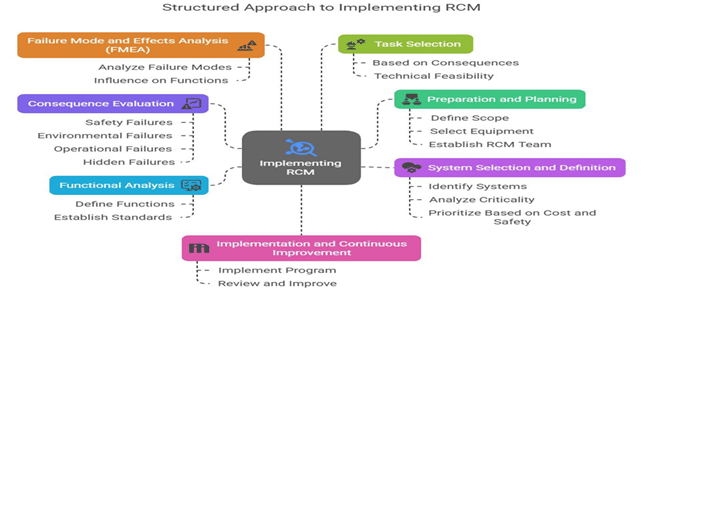
Many refineries “do maintenance” but not the right maintenance.
What works:
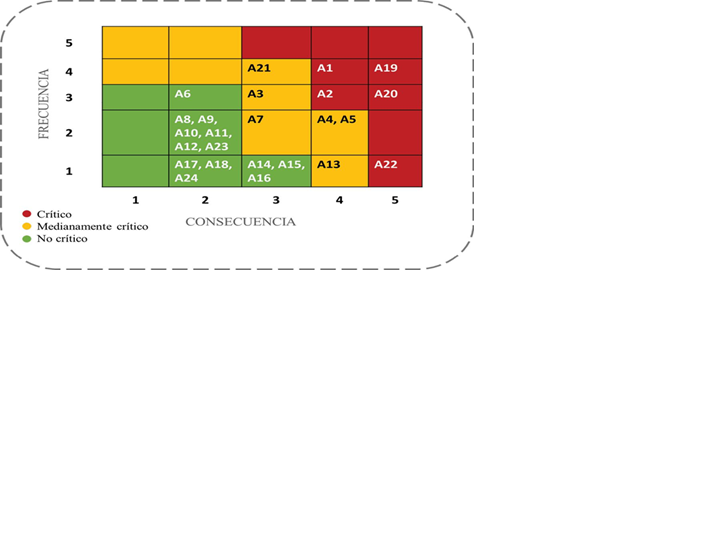
Conduct asset criticality ranking (safety, production, cost impact)
Apply Failure Modes and Effects Analysis (FMEA)
Eliminate unnecessary PM tasks that don’t prevent failure
Focus on failure prevention, not just routine servicing
Result: Less maintenance… but more effective maintenance.
3) Eliminate Bad Actors (Chronic Equipment Failures)
A small number of assets typically cause most downtime.
What works:
Track Mean Time Between Failures (MTBF)
Identify repeat offenders (“bad actors”)
Perform deep Root Cause Failure Analysis (RCFA)
Fix design/operational issues—not just symptoms (High temperature on process, cooling system issues, drainage issues, piping size issues, water treatment etc)
Examples:
Repeated pump failures → suction issues, cavitation, poor NPSH
Heat exchanger fouling → upstream contamination, poor filtration
Compressor trips → control logic or surge issues
4) Improve Turnaround (TAR) Planning & Execution
Poor shutdown planning creates both planned and unplanned downtime.
What works:
Freeze scope early (avoid scope creep)
Use detailed work packs and job sequencing
Pre-stage materials and tools
Conduct risk-based inspection before shutdown
Key metric:
Schedule adherence (%) — if it’s below 90%, there’s a planning problem.
5) Fix Maintenance Planning & Scheduling Discipline
Most downtime is not technical—it’s organizational inefficiency.
What works:
Separate planners from technicians (no dual roles)
Maintain a 2–4-week lookahead schedule
Ensure job readiness: permits, spares, drawings, manpower
Daily scheduling compliance tracking
Reality check:
If technicians spend time waiting for parts or instructions, downtime is inevitable.
6) Spare Parts & Inventory Optimization
Equipment often stays down longer due to missing or wrong spares.
What works:
Define critical spares for high-risk equipment
Standardization during design to enable interchangeability of spares.
Implement min/max inventory levels
Use kitting for planned jobs
Eliminate duplicate or obsolete inventory
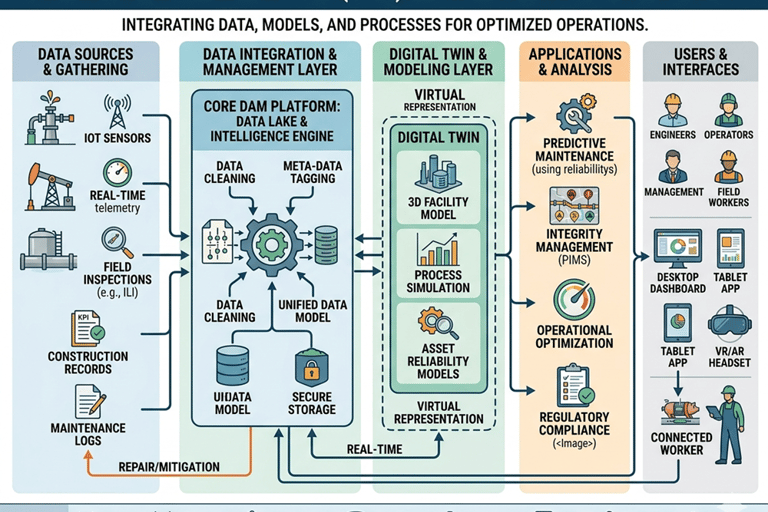
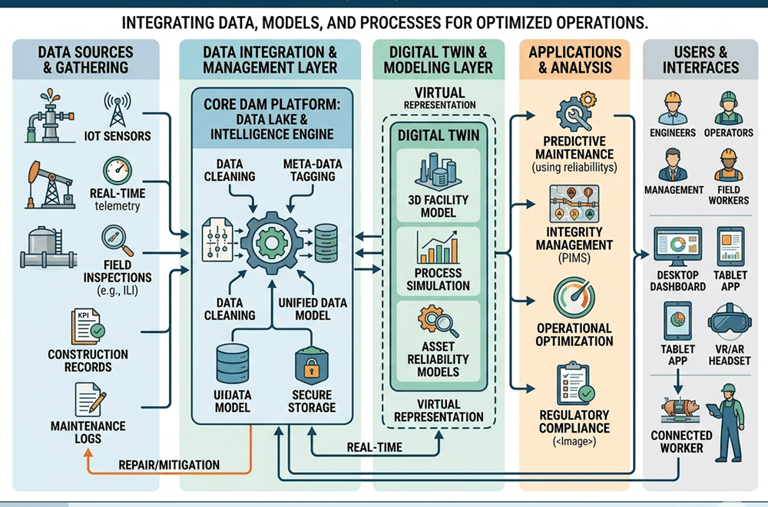
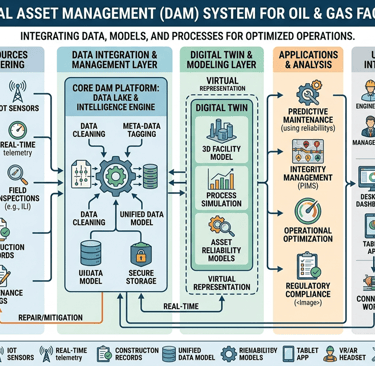
7) Digital Asset Management Systems (CMMS/EAM)
Data visibility drives better decisions—but only if used properly.
What works:
Use systems like SAP PM or IBM Maximo effectively (not just as a logbook)
Track KPIs: MTBF, MTTR, availability, backlog
Integrate condition monitoring data into CMMS
Avoid: Garbage in, garbage out. Poor data discipline kills value.
8) Operator-Driven Reliability (ODR)
Operators are your first line of defense.
What works:
Daily equipment checks (leaks, vibration, temperature, noise)
Basic care tasks: lubrication, tightening, cleaning
Early reporting culture
Impact: Many failures can be prevented before maintenance is even needed.
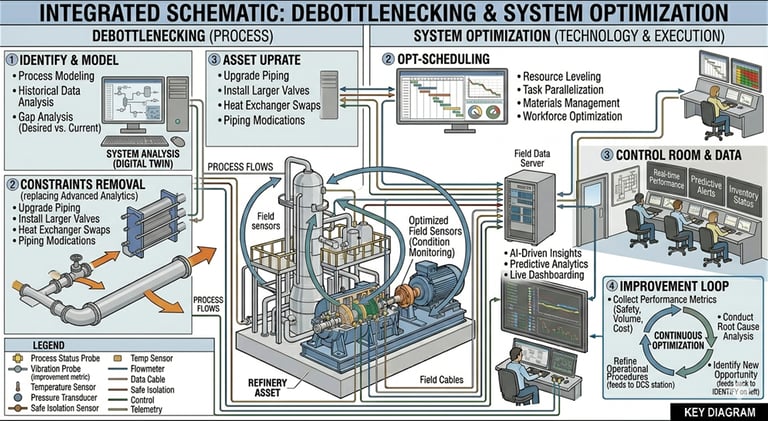
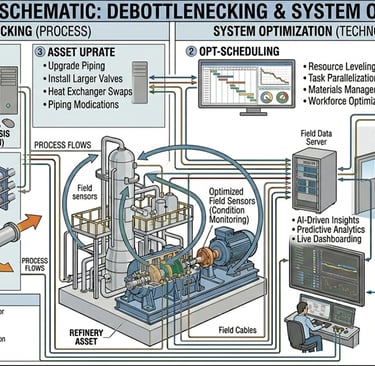
9) Debottlenecking & System Optimization
Sometimes downtime is caused by system constraints, not equipment failure.
What works:
Analyze process bottlenecks (pressure drops, flow restrictions)
Optimize control systems and setpoints
Upgrade undersized equipment
Example:
A compressor running near surge will trip frequently—this is a design/operation issue, not just maintenance.
10) Build a Reliability Culture
Technology doesn’t fix culture—people do.
What works:
Leadership commitment to reliability KPIs
Accountability at all levels
Cross-functional collaboration (Ops + Maintenance + Engineering)
Continuous learning from failures
🔑 Final Takeaway
Reducing refinery downtime is about discipline + data + engineering judgment:
Fix chronic failures (RCFA)
Predict problems early (condition monitoring)
Plan work properly (scheduling discipline)
Empower operators (ODR)
Use data intelligently (CMMS)